KubeflowにArtifactというデータなどを保存するための仕組みがある。Artifactを活用すると実験の履歴にどのデータを入力として使い、生成されたモデルがどれか?を紐づけて管理できるようになるらしい。
ということでArtifactを使えるようにしたいと思いいろいろ調べたけど、とりあえず動かすというサンプルがなかったので作ってみた。
多分AWSのS3とかGCSのStorageとかに保存するのだといろいろサンプルあるんだろうけどローカルでお試しするのがなかった。
結構四苦八苦したので、同じように困った人向けに公開しておく。
概要説明
- Windowsで動かしてるkubeflowで動作確認
- kubeflowのローカルストレージ(minio?)に保存するサンプル
- scikit-learnのirisデータをダウンロードしてpandas.DataFrameに変換して保存しただけ
所感
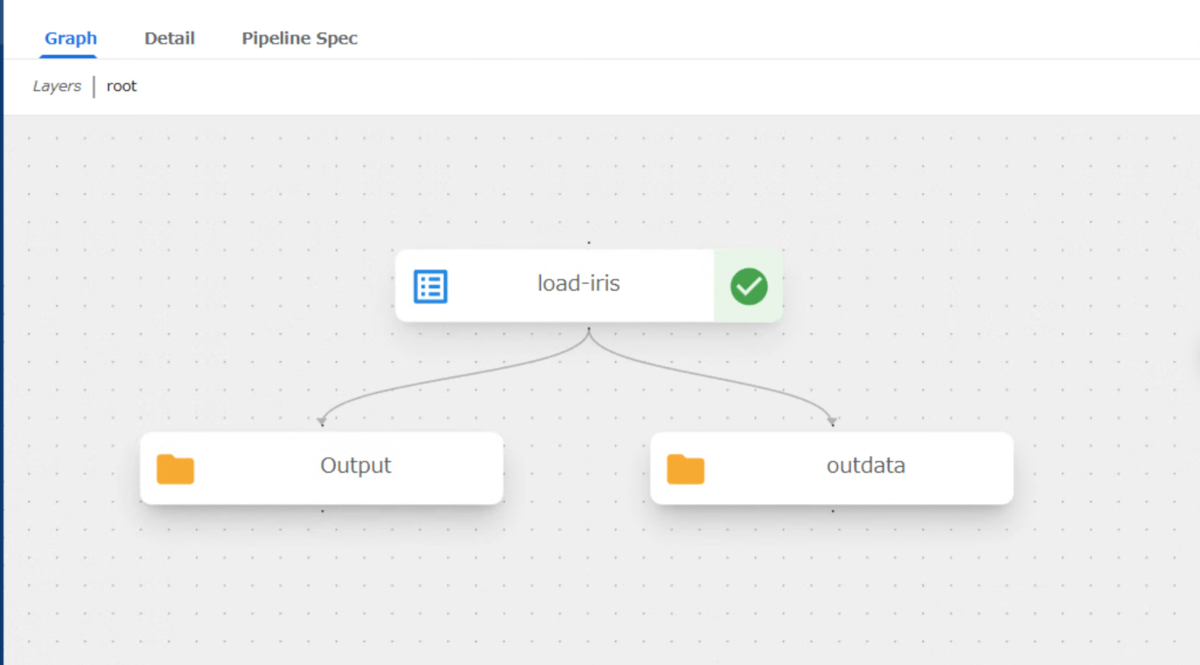
- 以下のpipelineの通り出力が2つできる。1つかと思ってた。
- 左がArtifactのmetadata?と思われる。
- 右のアウトプットが作成したデータ。なので利用する場合は右側のartifactを入力に使うことになるのかな?
- もしくは両方同じで左側のartifactをinputに指定するとartifact.pathが右のデータさすことになるんだろうか?この辺りはこれから試してみる。